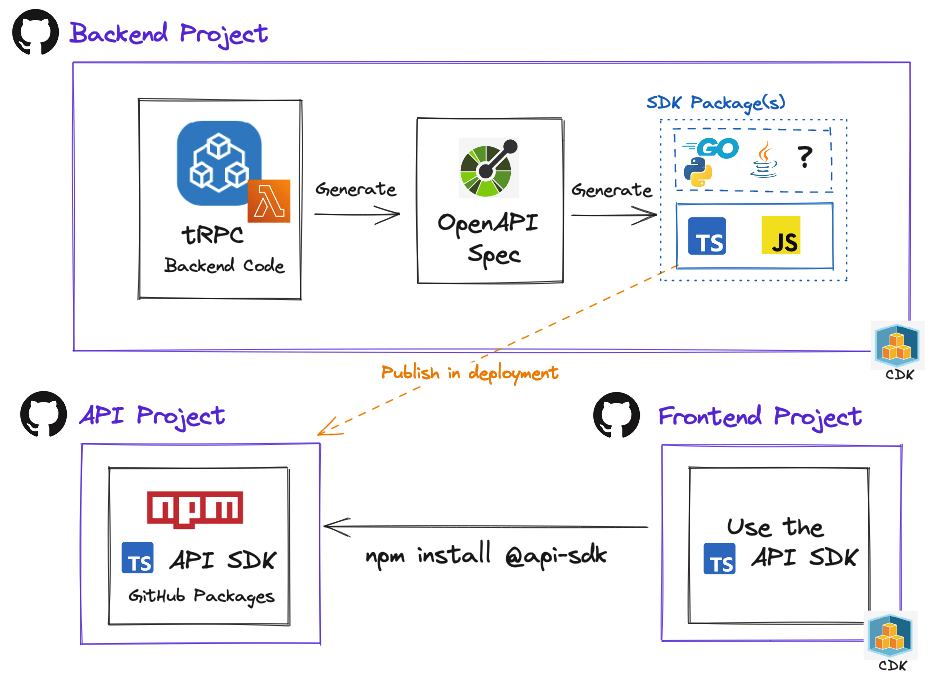
AWS Lambda with tRPC and separate repos using OpenAPI
By design, tRPC is meant to be used in a mono repo project. This should always be your default for tRPC projects if you can, if not then the best course of action is to generate an API SDK from the backend and consume it in the frontend.
In this blog we:
- Use a backend, frontend and API SDK repos running on AWS backed by the AWS CDK
- Showcases tRPC + trpc-openapi
- Generate an OpenAPI spec file from the tRPC code and then from that a JS API SDK, TS types and sourcemaps
- Show how the API SDK is pushed to the API repo and also published to GitHub Packages (similar to NPM)
- Use build system that consists of NPM scripts, wireit and a custom TS file used to execute commands
- Run tests setup for both unit and e2e and use breakpoints
- Show that local development is possible:
- By starting an Express server from the tRPC lambda code for the backend
- By starting the Vite dev server for the frontend
This is the alternative and better approach of the previous article, Improve DX by publishing an API SDK - a CDK Serverless example, I wrote to achieve a similar outcome. The GitHub projects are thus numbered -v2 as it has almost identical backend endpoints and frontend usage of the API.
In the previous solution, we started our experience by writing the OpenAPI spec and then generating TS types from that to be used in our backend project. Then the OpenAPI spec is converted into an API SDK and pushed to GitHub packages. This doesn't translate to the best DX (Developer Experience). It essentially makes our documentation (OpenAPI spec) the source of truth and uses multiple watch processes during development to generate types and validation. It's then also left to the developer to use them correctly and consistently.
We can do better and that is where tRPC enters the picture. By writing code first and then generating documentation (OpenAPI spec) from that, makes for a better and smoother DX. Now our code is the source of truth.
GitHub repos used in this blog:
A more involved example of tRPC usage in Lambda can be seen in this https://github.com/rehanvdm/serverless-website-analytics/tree/main/src/src/backend/api-front repo but is out of scope for this blog.
Backend
The backend project consists of an AWS CDK project that deploys a single Lambda function as the backend API. This Lambda-lith receives the API input through the Lambda Function URL (FURL) and then does the routing and validation using tRPC.
Application logic and tRPC
We will not go into too much detail when it comes to the AWS Lambda integration, you can see it in the tRPC docs here. I do want to highlight a few things that is not mentioned in the doc.
Do not directly export the trpc.awsLambdaRequestHandler as your function handler. So instead of this:
export const handler = awsLambdaRequestHandler({
router: appRouter,
createContext,
})Rather use it as a "black box" when it comes to tRPC things (routing, validation etc.). That way you can handle CORS, if not handled by your API GateWay. In this case, our API GW which is the FURL is handling it for us, so we don't need to do it ourselves. But we have a /docs route that returns HTML and tRPC can not handle that as it only works with JSON. This enables us to now catch this route and return HTML instead of passing data to our tRPC instance.
https://github.com/rehanvdm/pets-backend-v2/blob/main/src/backend/lambda/api/index.ts
function docsRoute(): APIGatewayProxyResult { }
export const handler = async (event: APIGatewayProxyEventV2, context: Context): Promise<APIGatewayProxyResult> => {
const ENVIRONMENT = getEnv();
console.debug('EVENT', event);
let response: APIGatewayProxyResult | undefined;
let trpcLastError: TRPCHandlerError | undefined;
try {
/* Handle paths that return non JSON outside tRPC */
if (event.rawPath === '/docs') {
response = docsRoute();
} else {
/* Do any rewrites here if you wish before passing to tRPC */
const trpcOpenApiHandler = createOpenApiAwsLambdaHandler({
router: appRouter,
createContext: ({ event }: CreateAWSLambdaContextOptions<APIGatewayProxyEventV2>) => {
return {
/* Add extra info to be used inside routes, add info about the user, do authentication and/or authorization here */
request: {
ip: event.headers['x-forwarded-for'] || '',
ua: event.requestContext.http.userAgent,
},
};
},
onError(err) {
trpcLastError = err;
},
});
response = await trpcOpenApiHandler(event, context);
response.headers = { ...response.headers };
}
} catch (err) {...} finally {...}
console.debug('RESPONSE', response);
return response;
};When it comes to the directory structure, you can follow any convention you want but I quite like making the routes/ directory mimics the path of requests.
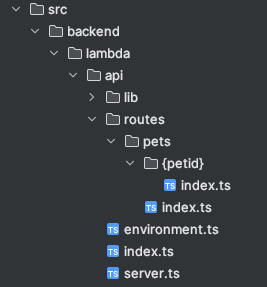
The trpc-openapi library is used to add the required OpenAPI info like path and method to the tRPC routes. This can be seen used below as .meta({ openapi: { method: 'POST', path: '/pets' } }). Also, note that we use Zod as runtime validation and then generate TS types from that for compile time.
https://github.com/rehanvdm/pets-backend-v2/blob/main/src/backend/lambda/api/routes/pets/index.ts
import { z } from 'zod';
import { Pet, SchemaPet } from '@backend/lambda/api/lib/models/pet';
import { TrpcInstance } from '@backend/lambda/api/server';
import * as db from '@backend/lambda/api/lib/db/pets';
const NewPetSchema = SchemaPet.pick({
type: true,
name: true,
});
export type NewPet = z.infer<typeof NewPetSchema>;
export function petCreate(trpcInstance: TrpcInstance) {
return (
trpcInstance.procedure
.meta({ openapi: { method: 'POST', path: '/pets' } })
.input(NewPetSchema)
.output(SchemaPet.array())
.mutation(async ({ input, ctx }) => {
const newPet: Pet = {
id: Math.ceil(Math.random() * 10000000),
type: input.type,
name: input.name,
};
db.addPet(newPet);
return db.getPets();
})
);
}
export function petGetAll(trpcInstance: TrpcInstance) {
return (
trpcInstance.procedure
.meta({ openapi: { method: 'GET', path: '/pets' } })
.input(z.void())
.output(SchemaPet.array())
.query(async () => {
const pets = db.getPets();
return pets;
})
);
}We can call generateOpenApiDocument from trpc-openapi to get back the OpenAPI spec. Below is a partial section of the file.
openapi: 3.0.3
info:
title: Pets API
description: Pets API
version: 0.0.6
servers:
- url: '-'
paths:
/pets:
post:
operationId: petCreate
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
type:
type: string
name:
type: string
required:
- type
- name
additionalProperties: false
parameters: []
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: array
items:
type: object
properties:
id:
type: number
type:
type: string
name:
type: string
required:
- id
- type
- name
additionalProperties: false
default:
$ref: '#/components/responses/error'
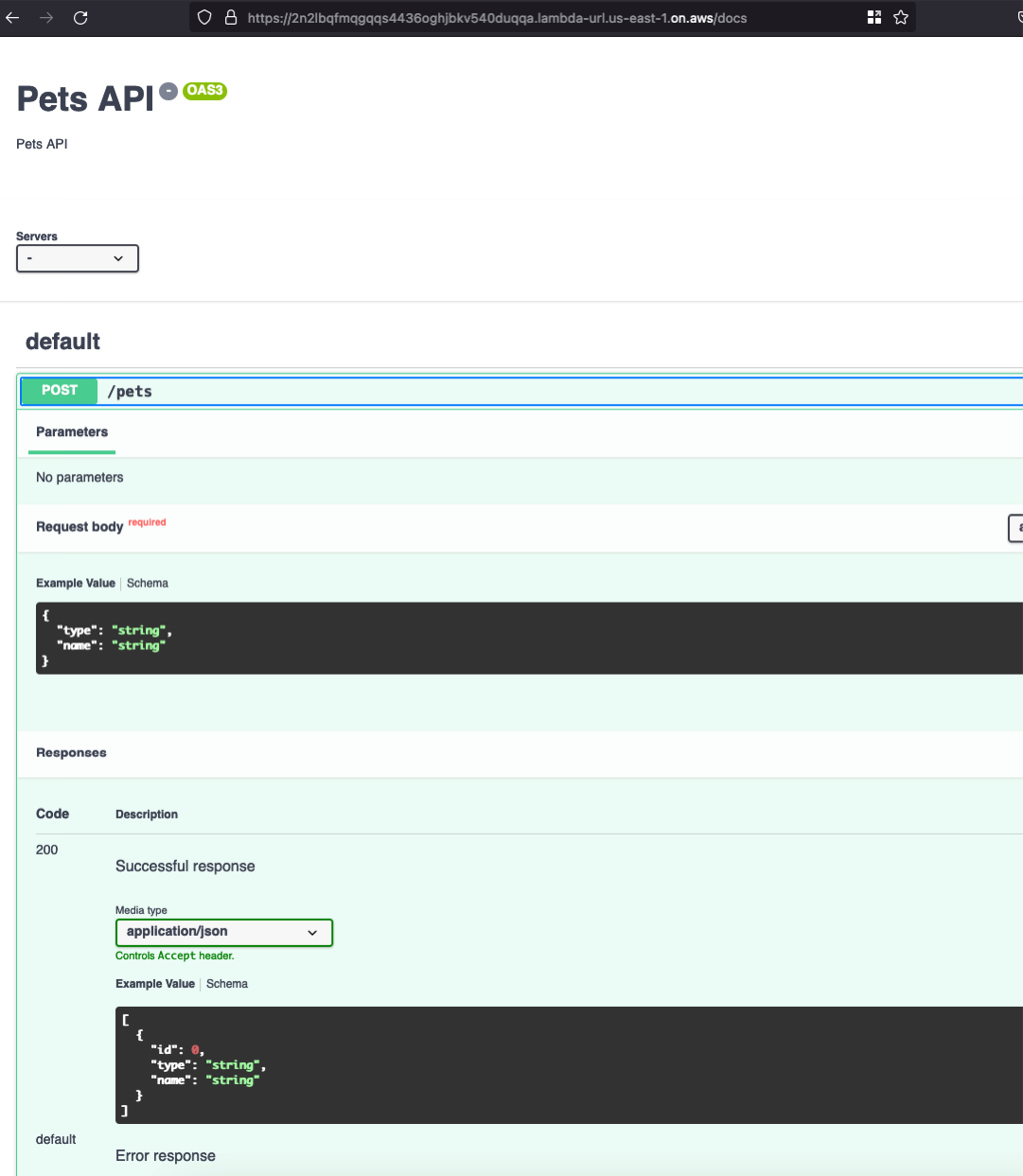
...We do exactly that by calling it in our API Lambda function and "embedding" the docs in our API. The following code runs on the /docs path and returns the OpenAPI spec formatted in pretty HTML.
https://github.com/rehanvdm/pets-backend-v2/blob/main/src/backend/lambda/api/index.ts#L14
function docsRoute(): APIGatewayProxyResult {
const applicationName = 'Pets API';
const openApiDocument = generateOpenApiDocument(appRouter, {
title: applicationName,
description: 'Pets API',
version: '-',
baseUrl: '-',
});
const openApiDocumentJsonObject = JSON.stringify(openApiDocument);
const body = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>${applicationName}</title>
<link rel="stylesheet" href="https://unpkg.com/swagger-ui-dist@3/swagger-ui.css">
</head>
<body>
<div id="swagger"></div>
<script src="https://unpkg.com/swagger-ui-dist@3/swagger-ui-bundle.js"></script>
<script>
SwaggerUIBundle({
dom_id: '#swagger',
spec: ${openApiDocumentJsonObject}
});
</script>
</body>
</html>`;
return {
statusCode: 200,
headers: {
'Content-Type': 'text/html',
},
body,
};
}Which produces the HTML:
Tests
There are unit and e2e tests that are used during development. In both cases, we are testing the Lambda function handler, not the tRPC implementation in isolation. The difference between the unit and e2e test is that the unit test will construct a JSON event and context and then directly call the function handler with it. This makes placing breakpoints for debugging possible. The e2e tests call out to the deployed AWS FURL API.
Tests are dual-purpose, meaning we only write 1 test and then an environment variable decides if it does a unit test or API call for e2e. We use the exact same test input, output and test criteria for both. When constructing the input for tests we use the tRPC types the Lambda function expects and in doing so get type safety for our tests as well.
https://github.com/rehanvdm/pets-backend-v2/blob/main/tests/backend/lambda/api/pets.test.ts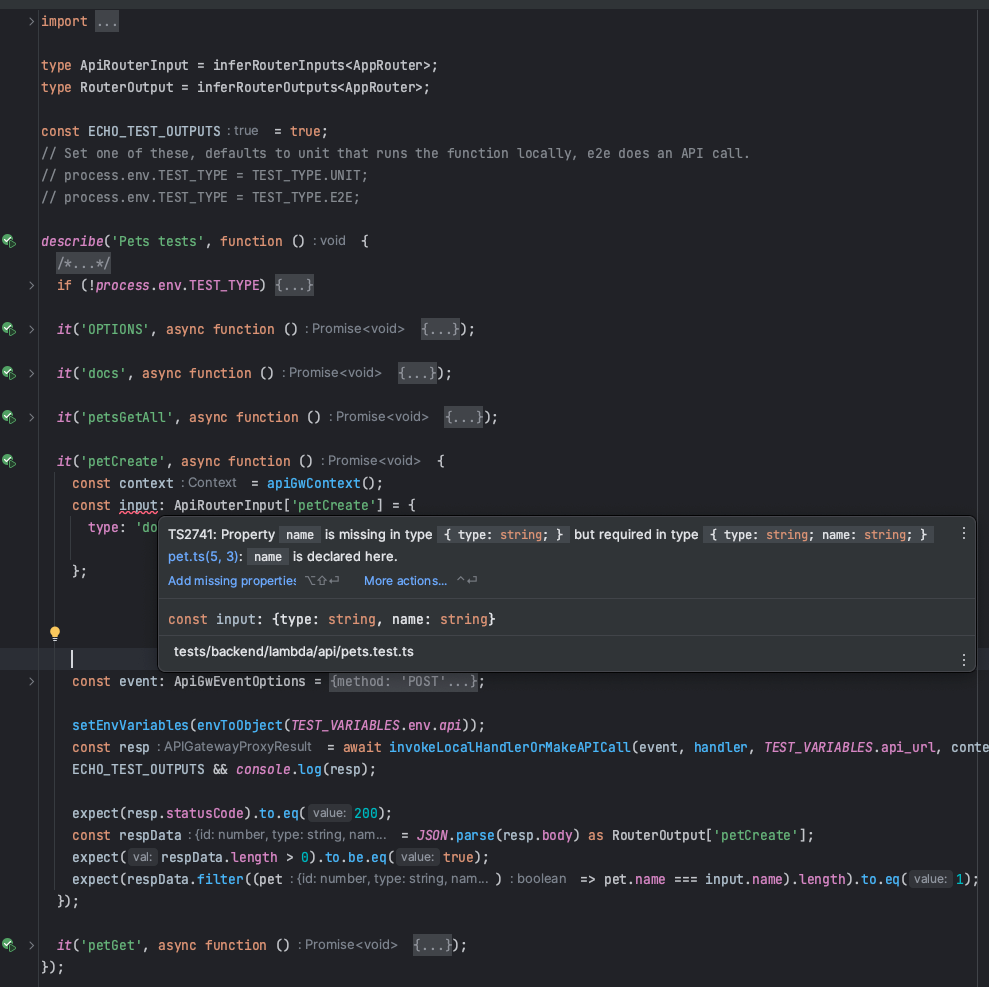
Tests are run using Vitest and when doing unit tests, you can place breakpoints to debug not only your tests but also the code you are testing.
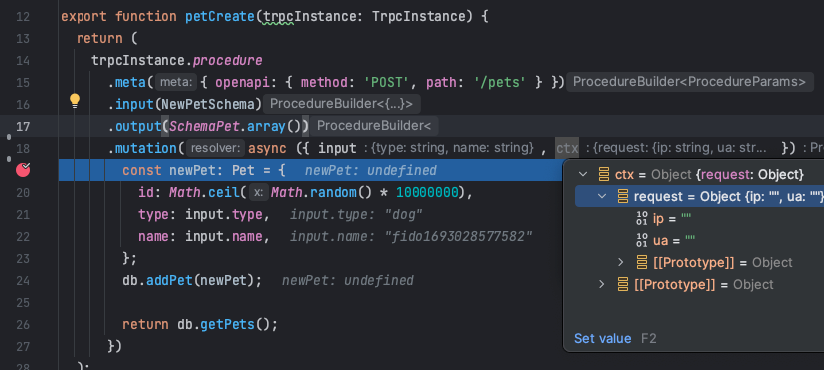
Local development
A basic Express app is used for the backend local development and a Vite dev server is used for the frontend local development. Having both local development servers running makes for better DX and improves the SDLC.
The Express app is handling CORS, just like our FURL on AWS would handle CORS for us. Then we just call our Lambda function handler by parsing the express request into an API GW request, very similar to the unit test. Which means we can also place breakpoints in our code.
https://github.com/rehanvdm/pets-backend-v2/blob/main/scripts/index.ts#L160
async function startLocalApi(port: number) {
console.log('STARTING..');
/* Set ENV variables */
setEnvVariables(envToObject(TEST_VARIABLES.env.api));
const app = express();
app.use(bodyParser.json());
app.use(cors());
app.use('/', async (req: Request, res: Response) => {
const context = apiGwContext();
const event: ApiGwEventOptions = {
method: req.method as 'GET' | 'POST' | 'OPTIONS',
path: req.path,
body: JSON.stringify(req.body),
headers: req.headers as { [p: string]: string },
pathParameters: req.params,
queryStringParameters: req.query as { [p: string]: string | undefined } | undefined,
origin: req.headers.host,
ip: '169.0.15.7',
ua: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.6,2 Safari/605.1.15',
};
const resp = await handler(apiGwEventV2(event), context);
res.status(resp.statusCode).set(resp.headers).end(resp.body);
});
const server = app.listen(port);
console.log('STARTED on: http://localhost:' + port);
return server;
}Running npm run start-local-api-watch in the backend project will run the above script and start the Express server on http://localhost:3000. The frontend dev server can be started using npm run dev and it will start on http://localhost:5174/ and use the local dev backend on port 3000 by default.
Building and Publishing the API SDK package
The npm run build-api-package command builds the API SDK with the following pseudocode:
- Generate the OpenAPI spec using
trpc-openapiand save it to disk in YAML format. This outputsopenapi.yaml. - Generate the TS API file(s) from the OpenAPI spec using the swagger-typescript-api package. This outputs
index.ts. - Transpile & bundle the TS API into JS using
esbuild. This outputsindex.jsandindex.js.map - Create types from the TS API using
tsc. This outputsindex.d.ts - Remove
index.tsas the source is no longer needed.
The npm run publish-api-package command builds and pushes the package folder to GitHib and then publishes a NPM package. The script can be seen here, it does a few extra checks like checking if the new version is more than the current etc. The end result that is published is shown below.
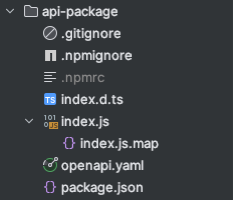
Frontend
The frontend project is used to demo the usage of the SDK API NPM packaged that is published by the backend project. It is a basic Vue app powered by Vite that uses the API SDK package in the /views/HomeView.vue file.
The API SDK package usage:
import {Api} from "@rehanvdm/pets-api-v2"
const apiBaseUrl = import.meta.env.VITE_API_URL;
const api = new Api({
baseUrl: apiBaseUrl,
// baseApiParams: {
// headers: {
// "Authorization": "<YOUR TOKEN HERE>"
// }
// }
});
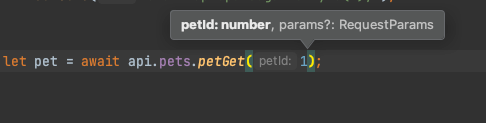
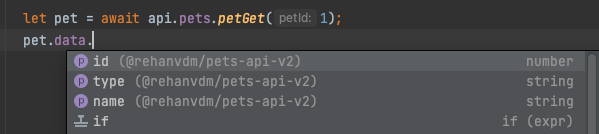
let pet = await api.pets.petGet(1);
console.log(pet);Note that you get autocomplete for the function (API arguments, with proper types) right in your IDE. 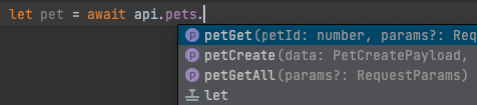
FAQ
Why can't we just export the tRPC AppRouter type and use that in the frontend
We can export the tRPC AppRouter type, but we can not bundle the other types that it uses. Let's look at an example, consider a piece of the AppRouter type generated with tsc.
declare module "routes/pets/{petid}/index" {
import { TrpcInstance } from "server";
export function petGet(trpcInstance: TrpcInstance): import("@trpc/server").BuildProcedure<"query", {
_config: import("@trpc/server").RootConfig<{
ctx: import("@backend/lambda/api/server").Context;
ctx: import("src/backend/lambda/api/server").Context;
meta: import("trpc-openapi").OpenApiMeta;
errorShape: import("@trpc/server").DefaultErrorShape;
transformer: import("@trpc/server").DefaultDataTransformer;
}>;
_meta: import("trpc-openapi").OpenApiMeta;
_ctx_out: import("@backend/lambda/api/server").Context;
_ctx_out: import("src/backend/lambda/api/server").Context;
_input_in: {
pet_id: number;
};
_input_out: {
pet_id: number;
};
_output_in: {
name: string;
type: string;
id: number;
};
_output_out: {
name: string;
type: string;
id: number;
};
}, unknown>;
}If the frontend were to use this Type, it would have to install the following packages:
trpctrpc-openapizod
This is because the exported Type makes reference to them like so:
import("@trpc/server").BuildProcedureimport("trpc-openapi").OpenApiMeta
This type of coupling is undesirable. Whenever you install a backend package that is used for constructing types, you will have to also install it for the frontend. This can be mitigated by installing the libraries and types in your API SDK NPM package and exporting them in the NPM package, thus hiding it from the user/installer.
But it is an uphill battle (and adds a lot of bloat) if you consider some of the imports are relative to the backend project only. Consider import("@backend/lambda/api/server").Context which is referring to a Type in the backend repo. The frontend will error and say that this type can not be found, because well it can't. TSC and the TS specification doesn't allow for bundling types. This might be supported soon though, see these issues relating to the issue:
- Monorepo mandatory ? - https://github.com/trpc/trpc/discussions/1860
- support to output declaration files or .dts on build or service.transform - https://github.com/evanw/esbuild/issues/95#issuecomment-1559710310
- --isolatedDeclarations for standalone DTS emit - https://github.com/microsoft/TypeScript/issues/47947
Why switch from AJV Standalone to Zod
AJV standalone is still one of the fastest runtime validation methods out there. The reasons I don't prefer it anymore:
- Requires multiple DIY steps at development time, making the DX a little rough around the edges
- The generated JS code grows quickly and every 100kbs has an impact on AWS Lambda cold start times
Zod on the other hand is almost 2 magnitudes slower but has a smoother DX. There is no need to fiddle with a DIY process and the bundle size will stay the same size no matter the amount of types that need to be checked.
The slowness is not noticeable if you consider that an API request does a lot of IO tasks. Therefore, is not even worth worrying about a few extra cycles for validation, it is nothing against the grand schema of things, like a network call inserting data into a DB.
If this wasn't an API and something that processes millions of records in a stream processing pipeline, then performance absolutely matters. AJV standalone will then be the better option. Actually, anything interpreted like JS is not the answer, consider a compiled language like Golang or something similar.
The generated OpenAPI spec does not include schema
This is because it only reads the Zod schema and strictly converts that into OpenAPI. It does group types/models together and reuse them across requests. You can modify the SDK generation library to also export all model types that you require on the frontend and then use them explicitly like that.