
Deep dive on ECS desired count and circuit breaker rollback
This post explores the available options for DesiredCount and the correlation with respect to time on the circuit breaker that initiates CloudFormation rollback. We will show how over scaling the DesiredCount on deployment for small/inactive services greatly reduces the time it takes for the circuit breaker to roll back on failure.
Desired count in CloudFormation
The DesiredCount parameter was made optional on 12 November 2020 as announced in the GitHub issue. There was no real announcement for this, it just got updated in the docs and I think many are still using hacks to work around it.
We are making following improvements to ECS integration with Cloudformation:
-- DesiredCount becomes an optional field in CFN CreateService and DesiredCount=1 would be used as the default value if it is missing
-- UpdateService will also omit DesiredCount when it is missing in CFN template
Customers expect the current behavior (i.e. UpdateService will use the set DesiredCount in the CFN template) can just add DesiredCount in their CFN templates. Existing customers wanting the new behavior can get it by removing DesiredCount from their CFN templates. The changes will be released soon.
Let's take the following scenario to understand why this update is so important. CloudFormation forcefully sets the DesiredCount when it is specified in a CloudFormation template. It will ignore the value previously set by auto-scaling.
- A deployed service with
DesiredCountset to 1 - Auto-scaling policies scales it out by setting the
DesiredCountto 10 - You deploy a new version of your app and CloudFormation sets the
DesiredCountback to 1
In this scenario, CloudFormation forcefully set the DesiredCount back to 1. It starts to deactivate and remove 9 tasks without taking into consideration the existing DesiredCount as set by autos-scaling. Your service is now overloaded, the demand exceeds the existing capacity and this directly affects your users in the form of timeouts or failed requests in the case of an API service.
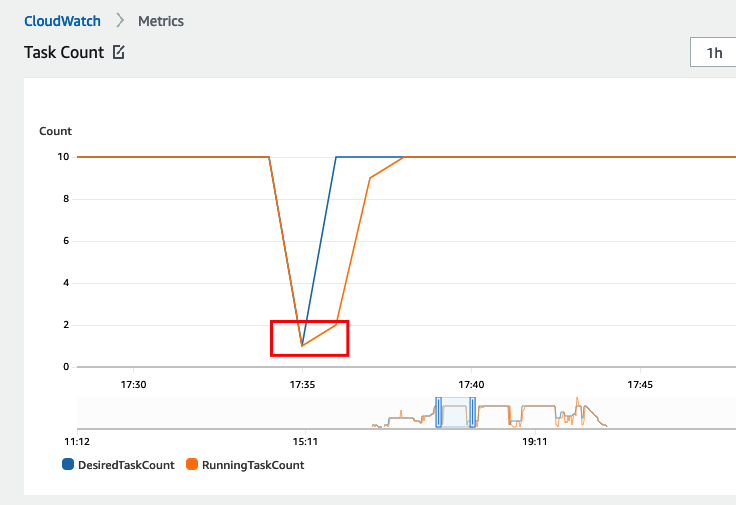
This behaviour forced people to create a lot of custom hacks, like looking up the DesiredCount with the AWS API/SDK and then setting it in CloudFormation before deploying.
We can now omit the DesiredCount as per the announcement because now ECS takes into consideration the current DesiredCount that is set at 10. It spins up 10 new tasks because the service minimum health is set to 100% and the maximum to 200%, then it deactivates the old tasks. This is the intended behaviour and will not impair our service like before when setting DesiredCount explicitly.
So going forward, you should not specify the DesiredCount parameter if you have autoscaling enabled.
Circuit breaker
AWS announced ECS deployment circuit breaker on 30 Nov 2020, which allows for automatic roll back of unhealthy service deployments without the need for manual intervention.
The circuit breaker is only used for failed deployments, it communicates the error from ECS back to Cloudformation in a timely manner so that a CloudFormation rollback can occur. This would then deploy the previous version of your stack and allows you to calmly fix the new version without having an impaired service.
It is enabled by specifying the DeploymentConfiguration.DeploymentCircuitBreaker property on the service.
Previously if the service was unable to reach a healthy state, the scheduler would retry deployments in perpetuity using the service throttling logic. Okay, technical it does not retry forever but 3 hours sure feels like forever when have to do a hotfix in production and now need to wait for the rollback to complete before being able to deploy again.
The new retry count is a function of the service's DesiredCount and is described in the docs here.
failed task threshold = minimum threshold <= 0.5 * desired task count => maximum threshold
failed task threshold = 10 <= 0.5 * desired task count => 200The deployment circuit breaker has a minimum threshold of 10 and a maximum threshold of 200 and uses the values in the following formula to determine the deployment failure.
Minimum threshold <= 0.5 * desired task count => maximum threshold
When the result of the calculation is less than the minimum of 10, the failure threshold is set to 10. When the result of the calculation is greater than the maximum of 200, the failure threshold is set to 200.
We can visualize this in a table varying the DesiredCount and determine how many failed tasks are required before the circuit breaker is triggered for rollback.
| DesiredCount | Formula | Failed task count threshold |
|---|---|---|
| 1 | 10 <= 1 * 0.5 => 200 | 0.5, so then 10 tasks |
| 10 | 10 <= 10 * 0.5 => 200 | 5, so then 10 tasks |
| 25 | 10 <= 25 * 0.5 => 200 | 12.5, so then 13 tasks |
| 100 | 10 <= 100 * 0.5 => 200 | 50 tasks |
| 500 | 10 <= 500 * 0.5 => 200 | 250, so then 200 tasks |
As expected, the DesiredCount is the only variable that determines how many failed tasks are required for the circuit breaker to trip and roll back. Next, we set the DesiredCount and observe the time it takes before the circuit breaker trips.
Desired count 1 ± 40 mins
When the DesiredCount is set to 1, ECS deploys 1 task after the other sequentially until it registers 10 failures and then rolls back. In the image below the DesiredCount before deployment is 1, it is kept at 1, but it deploys a broken container so that we can trigger the circuit breaker.
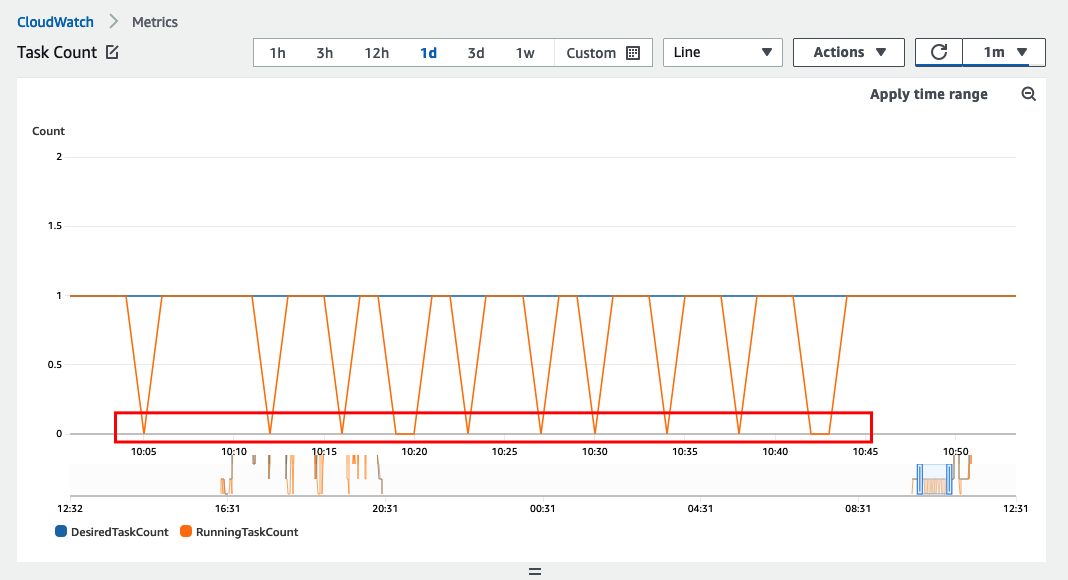
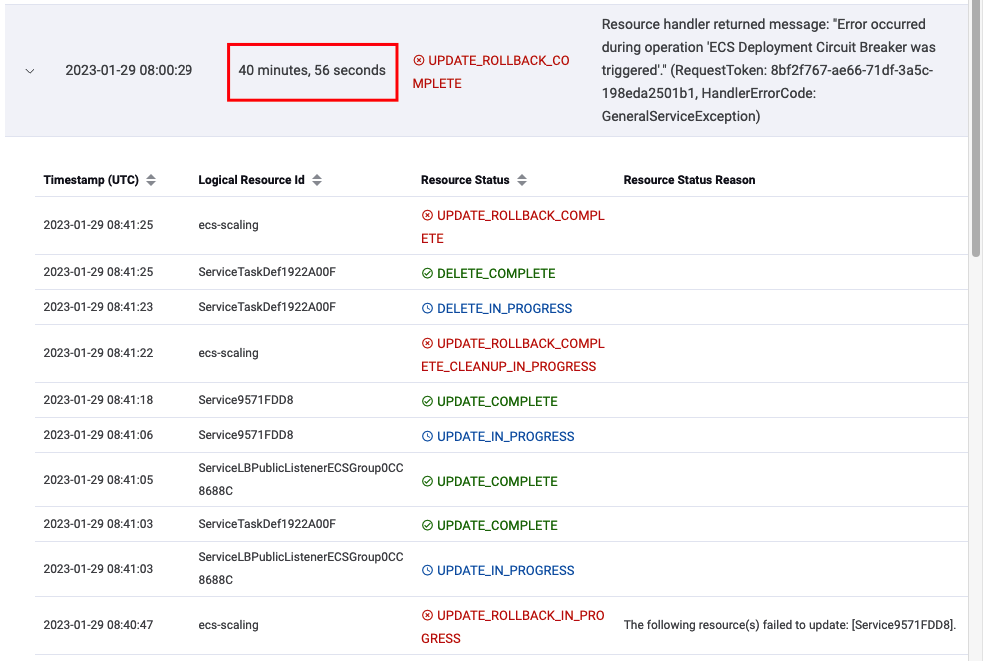
The CloudFormation deployment took about 40 minutes to complete.
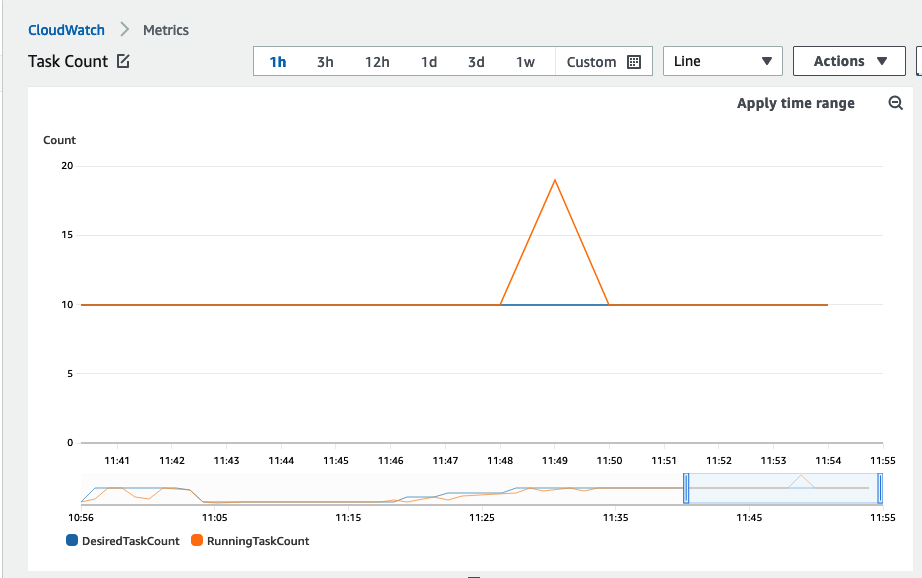
Desired count 10 ± 10 mins
When the DesiredCount is set to 10, ECS deploys 10 tasks in parallel until it registers 10 failures (which should happen at about the same time) and then rolls back. In the image below the DesiredCount before deployment is 1, it is then changed to 10 and also deploys a broken container so that we can trigger the circuit breaker.
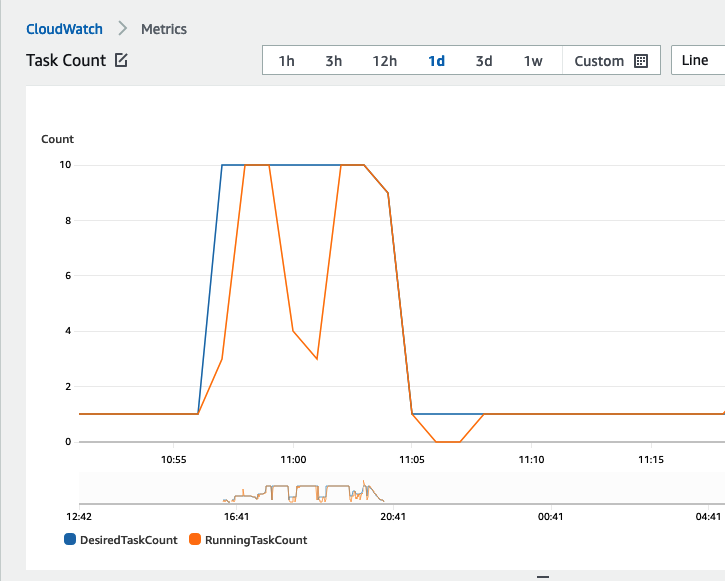
The CloudFormation deployment took about 10 minutes to complete
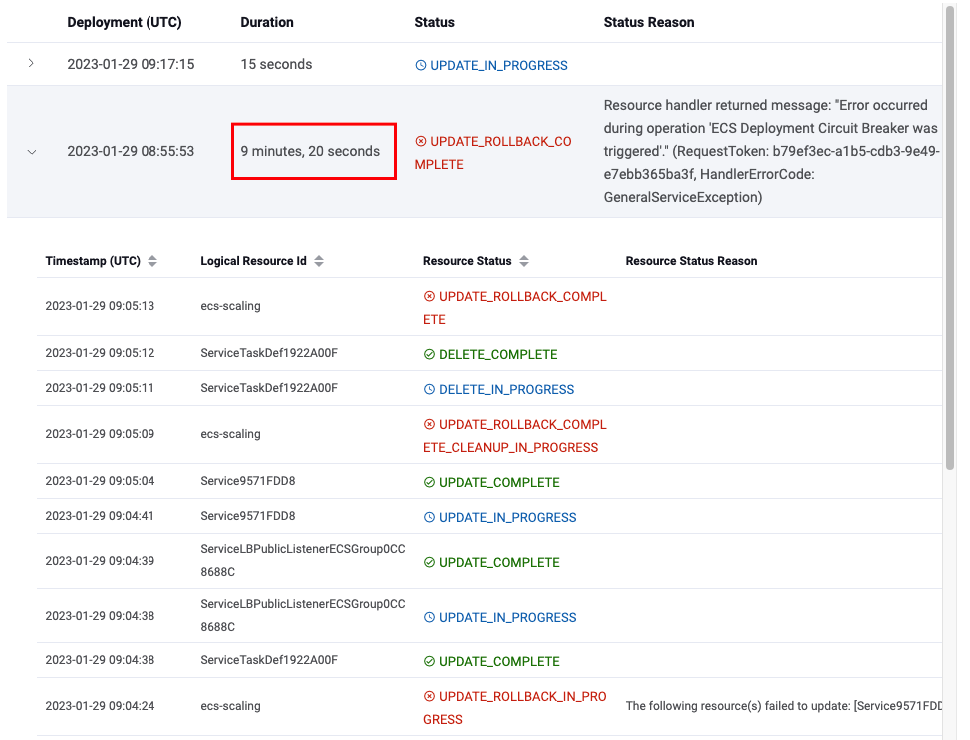
Controlling the time for rollback
Given that the failed task threshold and the time it takes for a container to become unhealthy are constant, then the time for the circuit breaker to kick in is indirectly proportional to the DesiredCount at deploy time.
circuit breaker time = (failed task threshold / desired count) * time to container healthcheck failedLet's take an example and define the time a container takes before reporting it is unhealthy as the sum of:
- The health check grace period, 1 min
- The health check failure counts, 3 with a timeout value of 30 seconds, so that means 1 minute 30 seconds.
This totals to 2 minutes 30 seconds before a container reports as unhealthy for a new deployment.
We can clearly see the effect of setting the DesiredCount has on the circuit breaker timeout when we compare the timeouts for the two DesiredCounts used in the example.
circuit breaker time = (10 / 1) * 2 min 30 sec = 10 * 2 min 30 sec = 25 min
circuit breaker time = (10 / 10) * 2 min 30 sec = 1 * 2 min 30 sec = 2 min 30 secIt reduces the deployment time from 25 minutes to 2 minutes and 30 seconds, which is 10 times faster!
You can further optimize this by reducing the time it takes for a task to be marked as healthy or unhealthy. Consider playing around with options like health checks, retries, timeouts and grace periods.
Over scaling on deployment
Over scaling on deployment is the only way to reduce the circuit breaker timeout and is only effective if the current task DesiredCount is less than 10.
Over scaling on deployment happens when we explicitly set the DesiredCount the same as the maximum of the auto-scaling policy, so:
desired count = maximum scaling policy
By doing this we ensure:
- That the circuit breaker rolls back as soon as possible by registering and deregistering multiple containers in parallel.
- Do not have an impaired service as we noticed before because the
DesiredCountwill never be set less than what was set by autoscaling.
This increases the tasks to their maximum after every successful deployment and might take a while to scale in depending on the number of containers and your scale-in policy.
In the image below the DesiredCount was 1 before deployment, it was then set to 10 in the deployment with a new task definition. This time the deployment succeeds and we can see how the DesiredCount scales up to 10 and then gradually scales back to 1 task as a result of auto-scaling.
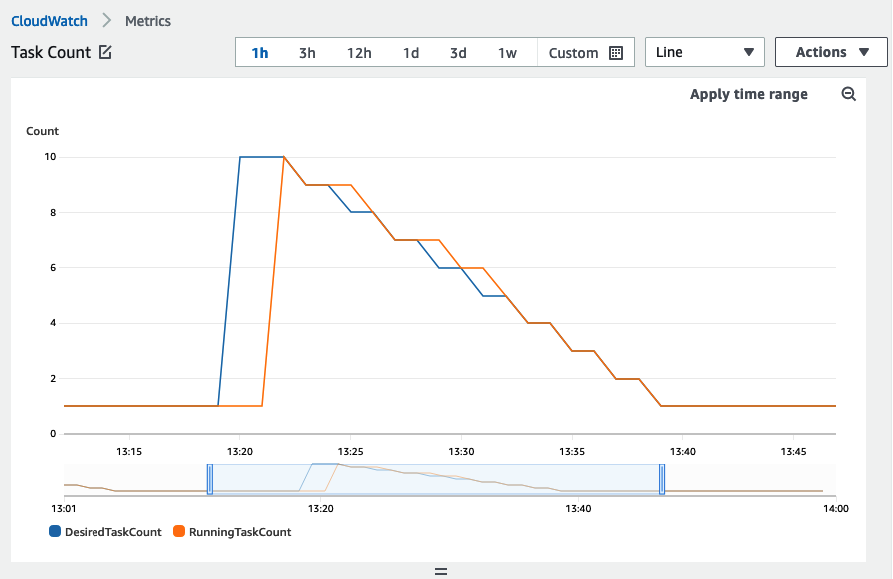
We also observe that CloudFormation completed successful.
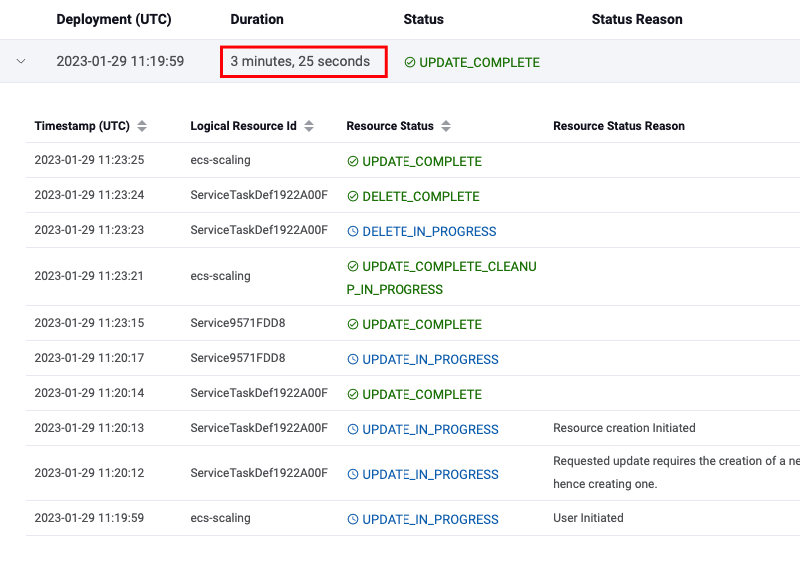
Something worth pointing out is how this affects your AWS bill. You should barely see a change in pricing given that:
- You don't deploy a thousand times a day otherwise, your average
DesiredCountwill lean towards your maximum task count. - Scaling in does not take too long so that you quickly return to your baseline
DesiredCountvalue as was before deployment.
Caveat for non API containers
Tasks that are fronted with an ELB (Elastic Load Balancer) have settings to prevent a scale-in event from terminating the container if it is serving traffic. When ECS scales in, the ELB will stop sending tasks traffic and deregister them in the deactivating phase. Ongoing connections are not closed immediately but are closed eventually after the deregistration_delay ( which defaults to 5 minutes) lapses.
Long-lived background tasks can not use this connection-draining feature of ELB. Consider the task is an SQS consumer, ECS can not know if your application is in the middle of processing a message when it wants to scale in. This means, it will kill your container while it processes the event and the message will return to the queue to be processed again after the visibility timeout lapses. This can cause problems if your processing is not idempotent.
This was the case up until 10 November 2022 when AWS launched ECS task scale-in protection. This has been a long-awaited feature as evident from this GitHub issue.
When using scale-in protection you can now rest assured that tasks will not be killed while they are processing. Application logic can now indicate when it is safe for a task to scale in, making this over scaling on deployment viable for all types of tasks.
CDK code use for this blog
The CDK code used for this blog can be found here: https://github.com/rehanvdm/ecs-scalng
I manually commented out parts to set the right conditions for the CloudWatch screenshots taken. An artillery load test ran on my local machine to generate traffic and trigger the task auto-scaling. Everything can be found in the repo.
import cdk = require('aws-cdk-lib');
import {Construct} from "constructs";
import * as ecs from "aws-cdk-lib/aws-ecs";
import * as ec2 from "aws-cdk-lib/aws-ec2";
import {SubnetType} from "aws-cdk-lib/aws-ec2";
import * as ecsPatterns from "aws-cdk-lib/aws-ecs-patterns";
import {AdjustmentType, MetricAggregationType} from "aws-cdk-lib/aws-applicationautoscaling";
export class Backend extends cdk.Stack {
constructor(scope: Construct, id: string, stackProps: cdk.StackProps) {
super(scope, id, stackProps);
const vpc = new ec2.Vpc(this, 'Vpc', {
ipAddresses: ec2.IpAddresses.cidr('10.0.0.0/21'),
subnetConfiguration: [
{
subnetType: ec2.SubnetType.PUBLIC,
name: 'Public',
cidrMask: 24,
},
],
natGateways: 0,
});
const cluster = new ecs.Cluster(this, 'Cluster', {
vpc,
enableFargateCapacityProviders: true,
containerInsights: true,
});
// https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_ecs_patterns-readme.html#application-load-balanced-services
const loadBalancedFargateService = new ecsPatterns.ApplicationLoadBalancedFargateService(this, 'Service', {
cluster,
assignPublicIp: true,
taskSubnets: {
subnetType: SubnetType.PUBLIC
},
memoryLimitMiB: 512,
cpu: 256,
taskImageOptions: {
// image: ecs.ContainerImage.fromRegistry("amazon/amazon-ecs-sample"),
image: ecs.ContainerImage.fromAsset("./src"),
},
minHealthyPercent: 100,
maxHealthyPercent: 200,
circuitBreaker: {
rollback: true,
},
// desiredCount: 1,
desiredCount: 10,
});
const scaling = loadBalancedFargateService.service.autoScaleTaskCount({
minCapacity: 1,
maxCapacity: 10,
});
scaling.scaleOnMetric('AggressiveCpuScaling', {
metric: loadBalancedFargateService.service.metricCpuUtilization({
statistic: 'Maximum',
period: cdk.Duration.seconds(60),
}),
adjustmentType: AdjustmentType.CHANGE_IN_CAPACITY,
scalingSteps: [
{ upper: 15, change: -1 },
{ lower: 40, change: +1 },
{ lower: 60, change: +3 },
],
datapointsToAlarm: 1,
evaluationPeriods: 1,
metricAggregationType: MetricAggregationType.MAXIMUM,
cooldown: cdk.Duration.seconds(60),
});
loadBalancedFargateService.targetGroup.configureHealthCheck({
/* Uncomment to break deployment and test ECS Circuit breaker */
// path: "/does-not-exist",
path: "/",
});
loadBalancedFargateService.targetGroup.setAttribute("deregistration_delay.timeout_seconds", "30");
}
}
export default Backend;Conclusion
There is only one method to achieve fast rollback times for small/inactive services with an auto-scaling policy that specifies a minimum less than 10.
Set the DesiredCount the same as the auto-scaling policy's maximum value which must be equal or more than 10, or in other words: desired count = maximum scaling policy.
This over scaling on deployment will ensure the circuit breaker quickly kicks in and rolls back if required. This method increases the tasks to their maximum after every deployment and relies on auto-scaling to reduce the DesiredCount after the deployment.
The circuit breaker will already kick in fairly quickly if you have an active service with more or equal to 10 running tasks. In this is case, it is best to not set desired capacity explicitly and omit it from your CloudFormation templates.
If you like deep dives, check out this excellent article by Philipp Garbe on ECS deployments.
Have you been frustrated managing multiple AWS accounts and regions?
Have a look at Cloud Glance:
- ✅ CloudGlance manages your
.aws/credentialsand securely generates temporary credentials with STS . MFA, SSO and Role are supported. - ✅ Open multiple AWS account consoles at the same time with Firefox Containers.
- ✅ Securely stores long-lived IAM credentials on disk, this encryption is opt-in.
- ✅ Port forwarding using either SSH or SSM
- ✅ Tracked Security Groups that sync your computer IP with the rules in an AWS Security Group.
- ✅ Unique multi-account & multi-region CloudFormation stack and events view. Events are grouped by deployment and show the first error alongside the final stack status.
Check it out here: https://cloudglance.dev/